Publication: 2024-07-03
Interpreting decimal strings into floats (Part 2) ¶
In the previous blog post, we saw how to parse a decimal string into a sign s, an integer n and an exponent e, such that the resulting value has an error of at most 2.71 \times 10^{-19} relative to the actual value represented by the decimal string (= 61 bits of precision).
The next step is to convert the base-10 pair (n,e) into the base-2 pair (m,p), such that n \times 10^e \approx m \times 2^p.
Reminder of the three steps required to interpret a decimal string into a float:
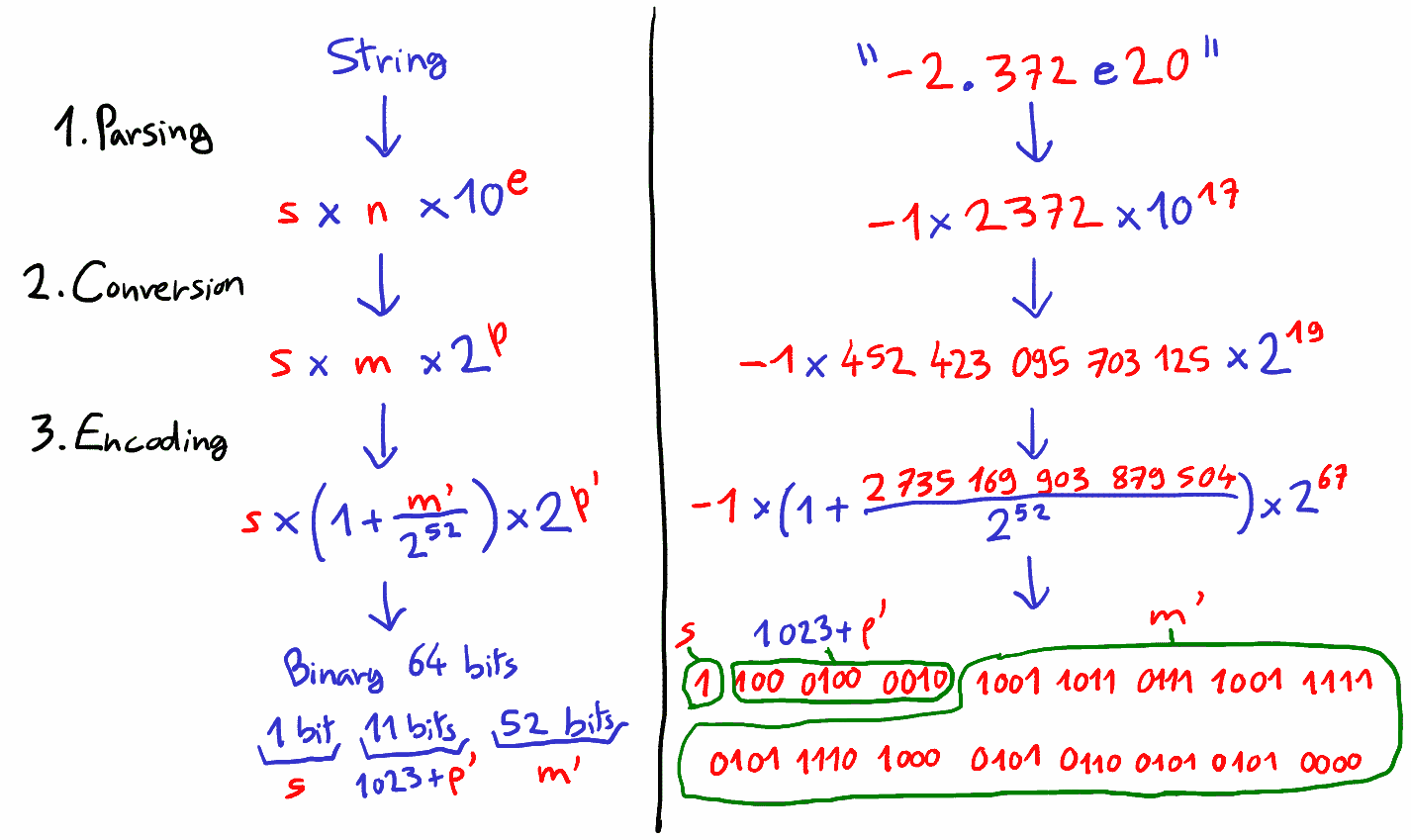
How to compute power of tens ¶
The trivial implementation for positive exponents e \ge 0 could be to compute the integer 10^e directly in an arbitrary-precision integer, to be multiplied with n, and finally the top bits of the computation are extracted. But we want to avoid arbitrary-precision integers, for performance and memory allocation concerns. Also, this is hardly expandable to negative exponents.
Instead, let's imagine we managed to get (a,b) such that 10^e = a \times 2^b instead, we obtain n \times 10^e = (n \times a)\times 2^b : we only need to compute (n \times a) with fixed precision, and extract the top bits. The difficulty becomes to find such (a,b).
One idea would be to precompute 10 = (a,b), then we have:
We need to do e-1 fixed-width multiplications to raise a to the power of e, at each step limiting the precision to 64 bits: we do e - 1 lossy computations, thus the margin of error is tremendous. Moreover, the execution time becomes linear to the magnitude of the number, which is bad.
A refined method is to use the square-and-multiply algorithm. The idea is to group redundant multiplications into squares, to reduce the number of intermediate multiplications.
The number of intermediate multiplications is logarithmic to the order of magnitude of the number, which is better. But in our use case, ten or so multiplications may be already too many lossy computations.
Alternatively, instead of computing the value at runtime, we can use a lookup table, pre-finding (a,b) and saving them into the program's data. Let's say we support exponents e \in [-512;511]: we need to store 1024 entries. Encoding a in 64 bits, and b in 16 bits, makes the table require 10 kiB of data. For some users, this may be affordable, but I want to have a smaller footprint.
Somewhat in between, I developed an hybrid approach: to decompose the exponent in three power of tens, lookup these values, and multiply them together. We suppose the exponent e is between -512 and 511. Note that 64-bit floats can represent at most about 10^{\pm 308}; so any exponent e greater than 512 will overflow, thus the encoded result is infinity, and any exponent smaller than -512 will underflow, the encoded result is zero.
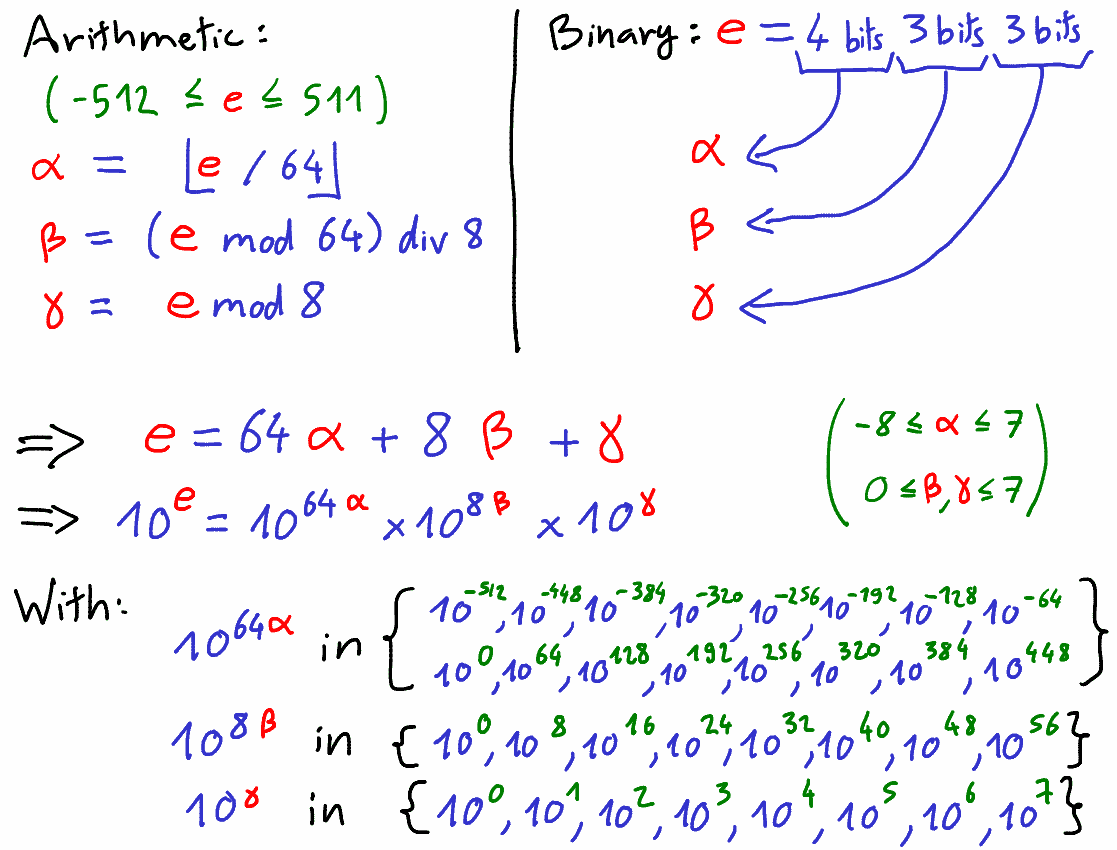
With this approach, we have exactly two lossy multiplications to compute 10^e, and an extra lossy multiplication to compute n \times 10^e. Our lookup table only requires 32 entries = 320 bytes, which I find reasonable. The next step is to generate this lookup table.
Generating the lookup table ¶
The lookup table being generated beforehand, we can use arbitrary-precision integers to find easily the best approximations stored in the lookup table. For this task, I found the Python shell to be a very competent calculator, notably using the fractions module in the standard library.
We want to find (m,p) such that m \times 2^p \approx 10^e. If we take p = 1 + \lfloor \log_2(10^e) \rfloor:
We get m a fractional number between 0.5 and 1. But m will be encoded as a 64-bit integer: to retain maximum precision, we should have 2^{63} \le m < 2^{64}. This can be applied by choosing instead: p = \lfloor\log_2(10^e)\rfloor - 63. Then, we have m \approx \frac{10^e}{2^p}. This translates in the following Python code:
def pow10(e: int) -> (int, int, float): # log2() only handle integers and floats, not fractions :( if e >= 0: p = math.floor(math.log2(10**e)) - 63 else: p = math.floor(-math.log2(10**-e)) - 63 # Using fractions to handle negative exponents losslessly f_pow10 = fractions.Fraction(10) ** e f_pow2 = fractions.Fraction(2) ** p m = round(f_pow10 / f_pow2) relative_error = abs((m * f_pow2) - f_pow10) / f_pow10 return (m, p, float(relative_error)) exps = (list(range(0,8,1)) + list(range(0,64,8)) + list(range(0, 512, 64)) + list(range(-512,0,64))) pow10s = [ pow10(e) for e in exps ] max_relative_error = max(p10[2] for p10 in pow10s)
With \text{max\_relative\_error} \approx 4.58 \times 10^-20 \approx 0.85 \times 2^{-64}.
We need now to determine how to multiply these numbers at runtime.
Multiplying two numbers ¶
Given two numbers a = (m_a,p_a) = m_a\times2^{p_a} and b = (m_b, p_b) = m_b \times 2^{p_b}, the multiplication of a and b gives:
p_a and p_b are way less than the 64-bit overflow limit, thus the addition is done without difficulty. But because m_a and m_b may be near 2^{64}, the multiplication result is represented on 128 bits, which we must shorten to 64 bits for further computation.
We will consider 2^{63} \le m_a, m_b < 2^{64}, which is the case for the power of tens stored in our lookup table. We need to fit the result r = m_a \times m_b into a 64-bit integer m_{ab}.
We know that 2^{126} \le r < 2^{128}. If we have r < 2^{127}, we multiply r by two and decrement p_{ab}, in order to keep the same encoded value but have 2^{127} \le r < 2^{128}. Thus, we take m_{ab} = \frac{r}{2^{64}}, in order to keep the invariant 2^{63} \le m_{ab} < 2^{64}.
The C code is:
// Compute (m, p) <-- (m, p) * (m2, p2) void _jvMultiply(uint64_t* m, int64_t* p, uint64_t m2, int64_t p2) { *p += p2; uint64_t low; uint64_t high = _jvMul64(*m, m2, &low); if (high < (1ull << 63)) { // Multiply (high, low) by 2 high <<= 1; high |= (low >> 63); // Carry low <<= 1; *p -= 1; // Compensate multiplication by 2. } // Rounding. Logically equivalent to `high += _jvAdd64(low, 2^63, &low)` and discarding 'low'. high += (low >> 63); if (high == 0) { // Overflow high = (1ull << 63); *p += 1; } *m = high; *p += 64; // We discard 'low', as if dividing by 2^64. }
The only problem remaining is the fact that the original n we need to multiply to the powers of ten is not necessarily greater than 2^{63}. This can be achieved by multiplying n by 2, until n \ge 2^{63}. We can implement this without loops by using CountLeadingZeros operation, which returns the number of multiplications by 2 we need to do; these multiplications can be done with a single bit-shift. Here is an example on 16 bits:
Because we are multiplying n by 2^{\text{clz}(n)}, we must correspondly decrease p by \text{clz}(n) in order to not change the encoded value.
The complete C implementation becomes:
uint64_t m = 0; int64_t p = 0; if (n == 0) { p = INT64_MIN; goto end_of_compute; } // Pack 'n' into the high bits of 'm', such that 'm >= 2^63'. int64_t clz = _jvClz64(n); m = n << clz; p = -clz; // Only compute exponents such as 10^[-512;+511] if (exp < -512) { // Underflow to ZERO. m = 0; p = INT64_MIN; goto end_of_compute; } else if (exp > 511) { // Overflow to INFINITY. m = UINT64_MAX; p = INT64_MAX; goto end_of_compute; } uint64_t idx; idx = exp & 0x7; _jvMultiply(&m, &p, _jv_TABLE_M[idx], _jv_TABLE_P[idx]); idx = 8 + ((exp >> 3) & 0x7); _jvMultiply(&m, &p, _jv_TABLE_M[idx], _jv_TABLE_P[idx]); idx = 16 + ((exp >> 6) & 0xF); _jvMultiply(&m, &p, _jv_TABLE_M[idx], _jv_TABLE_P[idx]); // Result: (m, p)
Margin of error ¶
In the complete code showcased before, the only lossy computations are done inside _jvMultiply, when we keep 64 bits from a 128-bit result. First, let's consider the case where the function retains full precision during its computation.
Given the two operands N_a = m_a \times 2^{p_a} and N_b = m_b \times 2^{p_b}, with 2^{63} \le m_a,m_b < 2^{64}, the multiplication finds (m_{ab}, p_{ab}) such that N_{ab} = m_{ab} \times 2^{p_{ab}} = N_a \times N_b, where 2^{63} \le m_{ab} < 2^{64}. Two cases are possible:
We can fold these two cases into one expression:
Now, we consider that m_a, m_b and m_{ab} are not encoded exactly, but approximated respectively by m_a', m_b' and m_{ab}', so the actual encoded operands are N_a', N_b' and the actual encoded result is N_{ab}'.
Given the relative errors \varepsilon_a > |\frac{N_a' - N_a}{N_a}| and \varepsilon_b > |\frac{N_b' - N_b}{N_b}|, we want to find the relative error \varepsilon_{ab} > |\frac{N_{ab}' - N_a N_b}{N_a N_b}|. The proof requires 4 intermediate results:
1. The relative error can be expressed only with m parts :
2. The relative error can be bound (starting from the definition of m_{ab}') :
3. \frac{m_a' m_b'}{m_a m_b} - 1 can be bound with the relative errors \varepsilon_a and \varepsilon_b :
4. \frac{2^{63-R}}{m_a m_b} is bound by 2^{-64} :
Then, by merging the four parts together, we get:
We have the expression of the error produced by the multiplication: it is now time to put some numbers into the formulas. We multiply four numbers and their own relative error:
-
n, with error \varepsilon_n \approx 2.71 \times 10^{-19}
-
10^\gamma, with error \varepsilon_\gamma = 0 \quad (10^0 ... 10^7 are encoded losslessly)
-
10^{8\beta}, with error \varepsilon_\beta \approx 4.58 \times 10^{-20}
-
10^{64\alpha}, with error \varepsilon_\alpha \approx 4.58 \times 10^{-20}
The cumulative errors of the three multiplications are:
Thus, at the end, we get the final relative error \varepsilon = 3.26 \times 10^{-19}.
Summary ¶
With this blog post, we have done the second third of the road to interpret decimal strings into floats. We know have computed m \times 2^p such that the relative error is \varepsilon = 3.26 \times 10^{-19}, relative to the actual number encoded by the arbitrary long decimal string.
In the next blog post (and last implementation post), we will tackle the encoding (s, m, p) as 32-bit and 64-bit floating point numbers.
Thanks for reading, have a nice day!
Attribution ¶
"Math time" image : Math Vectors by Vecteezy
Flames image : By Carmelo Madden on pngset.com